
tl;dr: all workshop materials are available here:
https://rstd.io/conf20-dl
License: CC BY-SA 4.0
This past January I attended rstudio::conf(2020). Seems odd to say that I attended a conference in 2020 but I did, along with over 2,000 others. This was my second rstudio::conf and if you have not attended, you definitely need to put it on your radar for future years - the people, community, resources and education are great bar none.
This year I had the opportunity to teach the Deep Learning with Keras and TensorFlow in R workshop. The workshop had max capacity attendence and was sold out within the first couple of months of opening up; showing a strong thirst for deep learning within the R community. With unbelievable support from TAs and RStudio, the workshop was a great success.
State of deep learning resources
There is no lack of deep learning resources. Almost any tech learning platform you look at (i.e. coursera, Udemy) is filled with deep learning courses, publishers are filling virtual deep learning bookshelves, and deep learning blog posts are a dime a dozen. But with all these resources I often find two road blocks for people being able to understand and implement deep learning solutions:
- Often the material over-emphasizes algorithmic complexity and uniqueness of deep learning. However, when you simplify most deep learning methods down to their basic ingredients, people that understand basic statistical concepts and common “shallow” learning models such as linear regression can fully grasp deep learning concepts.
- Most material use Python and leads R programmers to think that they need to leave the comfort of their current language to do deep learning tasks.
This workshop was designed to debunk both of these myths and provide an intuitive understanding of the architectures and engines that make up deep learning models, apply a variety of deep learning algorithms (i.e. MLPs, CNNs, RNNs, LSTMs, collaborative filtering), understand when and how to tune the various hyperparameters, and be able to interpret model results…all with the simplicity, comfort and beauty of R! 1
So how did we approach this?
Understanding the ingredients
The first 90 minutes we spent working through a notebook that illustrates how feedforward deep learning models solve very simple linear regression, binary and multi-class classification problems. We simplified these procedures to the bare minimum so folks can understand:
- how the model architecture relates to common models they’ve used before,
- how the models learn via gradient descent,
- what activation functions are,
- the idea of learning rate and momentum,
- how model capacity impacts performance,
- why we care about batch sizes,
- and the importance of data prep.
Wow, that seems like a lot…and it was! But by working through very simple examples and illustrations the students started to realize that these concepts are not overly complicated. In fact, many started to see a very obvious relationship to non-deep learning concepts they already know.
Follow a recipe
After getting a basic understanding of key deep learning concepts and terminology, we spent the rest of the morning discussing how to strategically approach training a deep learning model. I’ve gotta admit, finding an optimal deep learning model is far more difficult and time consuming than traditional shallow models. In fact, its rare that you will actually find an optimal model!
As data scientists we can accept this but we still need to have a good mental model that gives us a high probability of finding a near optimal one while reducing overall model exploratory time. For deep learning models, this can be reduced to:
- Prepare data
- Balance batch size with a default learning rate
- Tune the adaptive learning rate optimizer
- Add callbacks to control training
- Explore model capacity
- Regularize overfitting
- Repeat steps 1-6
- Evaluate final model results
Once folks understood what each one of these steps were doing and how to implement them, they definitely gained confidence in their ability to apply an initial model and then start iterating to improve model performance.
A basic cookbook
Once students had a good mental model of the basic ingredients of deep learning models and a general recipe for approaching training models, the rest of the workshop was spent building on top of a basic feedforward model and working through the concepts of:
- computer vision with convolution neural networks,
- the idea of re-using previously trained models (aka transfer learning),
- encoding text with word embeddings,
- applying a deep learning approach for collaborative filtering with customized functional models,
- using recurrent neural networks and long short term memory networks for analyzing sequential data (i.e. text, time series, videos).
Each of these models builds onto the foundational knowledge with new key concepts. Along the way we trained over a dozen different types of models and data sets…some small and some big. But working through these different concepts gave folks the exposure to common problems where deep learning shines and also where some models have a hard time improving over a simpler shallow classification model.
Workshop approach
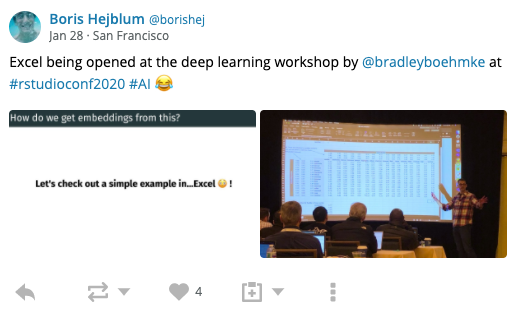
As you may infer, the workshop was very hands-on and covered a lot of material using a variety of approaches. If you peruse the repo, you will notice that we worked through notebooks for interactive analysis, used slides to emphasize key concepts and illustrations, and even opened up an Excel file to help demonstrate what’s going on with basic collaborative filtering and word embeddings!
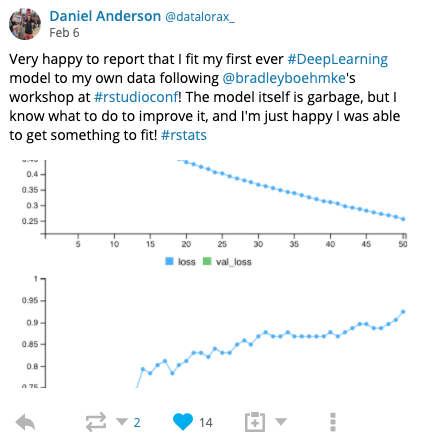
In fact, I knew going into the workshop that I probably had too much material. But my hopes was that the workshop provided an opportunity to explore the concepts while also allowing folks to easily work through notebooks and compare solutions on their own. So if you missed out on the workshop, all the data and code to reproduce the notebook content and slides are available. I even provide extra content that we didn’t have time to cover such as visualizing CNN models, performing grid searches, and more.

Plus, all the content is licensed as CC BY 4.0 so people can feel free to reuse slides, notebooks, exercises and the like.
Appreciation
I had an absolute blast developing and delivering this workshop. The attendees were fantastic and asked valuable (and challenging!) questions; making the 2-days very interactive and personable.
The workshop was also result of a fantastic TA team! I really enjoyed meeting and getting to know them:
I also could not have pulled it off without the incredible RStudio infrastructure team dedicated to supporting us ( Cole Arendt and Alex Gold) and the entire RStudio Education team. The infrastructure team made using AWS and GPUs as simple as making pop tarts and the education team made everything smoooth and seemless!
Enjoy!
I hope the materials developed for this workshop are useful to learners and educators alike. If they are, please let me know, I’d love to hear about it.
-
This is not to say that some deep learning concepts don’t become extremely complex; however, I would argue that they are no more complex than advanced extensions of generalized linear models…GAMs anyone??? Also, I am a huge proponent of learning multiple programming languages so this has nothing to do with the ridiculous R vs Python vs … argument! In fact, the more you know about Python the easier it is to debug Tensorflow and Keras problems within R. ↩︎